
Introduced in Chapter 1, SQL Server Integration Services (SSIS) is useful for pulling data from numerous datastores, transforming the data, and storing it in a central datastore for analysis. Ingestion can be initiated by pulling data from existing sources instead, which is in contrast to data producers pushing data into the pipeline.
Bulk Copy Program
There are scenarios in which you have numerous files you want to load to Azure once or occasionally and not on a regular schedule. In those cases, there is no need to create a process since that kind of activity is typically done manually. In this case, using a bulk copy program (BCP) to upload the data is a good option. Azure Storage Explorer, which uses a popular application called AzCopy under the covers, is a solid tool for uploading files from a local source to an Azure Data Lake Storage container.
Streaming
Data streaming implies that there is a producer creating data all the time and sending it to an endpoint. That endpoint can be numerous products like Apache Kafka, Azure IoT Hub, or Azure Event Hub, which are designed to handle and temporarily store data at extremely high incoming frequencies. Those products are not intended to be stored for long periods of time; instead, when data is received, those products notify subscribers that data is present. Then those subscribers take an action that is dependent on their requirements and use of the data.
Prepare, Transform, Process
Once the raw data is ingested, whether via streaming, bulk, pulling from a data source, or using PolyBase, it then needs to be transformed. The data can come from numerous data sources and be in many different formats. Transforming this data into a standard format results in a larger set of shared queries and commands being run against it. If you needed to run a unique query against data from each data source, using all the data wouldn’t lead to the optimal conclusion. Instead, merge and transform all the data into a single source and format, then run a single set of queries or commands against it. The result will be much more encompassing thanks to the wider set of data diversity. The movement and transformation of data in this stage has much to do with data flow.
Data Flows and Pipelines
Data flow is the means by which you manage the flow of your data through a transformative process. As you can see in Figure 2.31, data is retrieved, transformed, stored into a staging environment, and placed into an Azure SQL database using an Azure function. Notice the notebook; this is where you can run all the queries and commands you have learned in this chapter. Once you have the query, commands, or code you need to perform the transformation, save them and they will run as a pipeline that includes a data flow transformation activity. This explanation is only an introduction, and you will get some hands‐on experience with this later in this book.
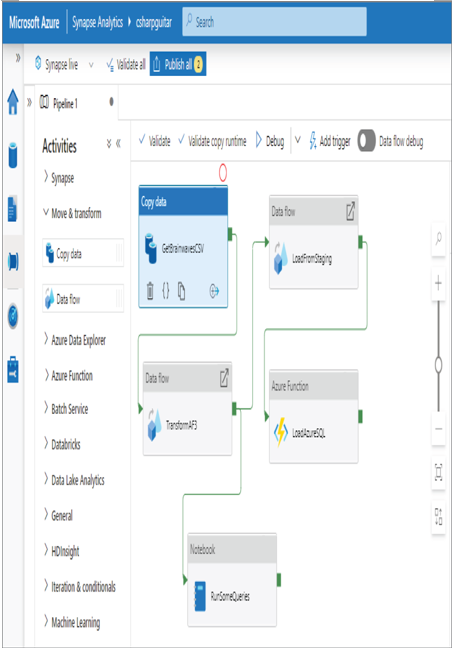
FIGURE 2.31 Pipeline data flow Azure Synapse transform stage
This data flow activity is available in both Azure Synapse analytics and Azure Data Factory. Figure 2.31 represents what is commonly referred to as mapping data flows. An alternative is called wrangling data flows, which is currently only available in Azure Data Factory, as is the Power Query Online mashup editor. The primary difference between the two flows is that mapping data flows has a focus on visually representing the flow between sources, transformations, and sinks, whereas wrangling data flows provides more visualization on the data, giving you quick visibility on what the end dataset will look like. Both do not require any coding to perform the data transformation.



