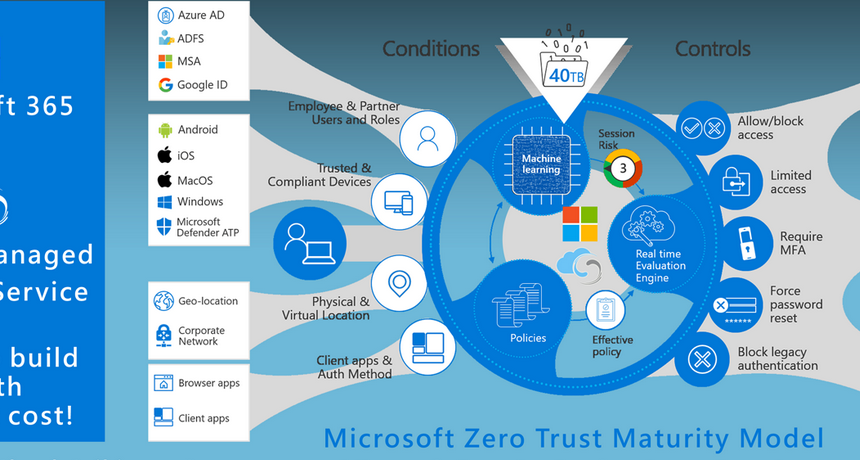
Both efficiency and performance were discussed in earlier sections pertaining to the design of a partition strategy. An efficient query is one in which the time required to execute it is well used. That means the query should not be waiting on data shuffling or querying irrelevant data. The most efficient query would be one […]